VŠB - Technická univerzita Ostrava
FAKULTA STROJNÍ
Katedra automatizaèní techniky a øízení
ul. 17. listopadu 15,
708 33 OSTRAVA - PORUBA
VŠB - Technická univerzita Ostrava |
Databázové systémy
Microsoft Access 2.0
Radim Farana
Ostrava 1995
Copyright © Ing. Radim Farana, CSc.
Lektoroval : Ing. Milena Olivková
Databázové systémy. Microsoft Access 2.0
Názvy programovưch produktù a firem mohou bưt ochrannưmi známkami nebo registrovanưmi ochrannưmi známkami
pøíslušnưch vlastníkù.
S rozvojem lidského poznání roste prudce množství informací, které tento proces vyžaduje a také produkuje. Pro efektivní práci s informacemi zaèaly vznikat specializované informaèní systémy. Mùžeme je definovat napø. jako : "systémy pro sb́r, uchovávání, vyhledávání a zpracovávání informací (údajù, dat) za úèelem jejich poskytování". Tvorbou informaèních systémù se zabưvá v́dní obor Informatika, vyd́lenư v nedávné dob́ z oboru Kybernetika.
Rozvoj informaèních systémù je úzce spjat s rozvojem vưpoèetní techniky, zejména poèítaèù. Od svưch poèátkù byla využívána na zpracování velkưch informaèních objemù na jednom poèítaèi. Takové systémy obvykle nazưváme systémy hromadného zpracování dat nebo agendové zpracování. Data se nejprve ruèń zaznamenávají na stanovené formuláøe, dále se pøepisují na vhodné médium (d́rné štítky, diskety), následuje primární a sekundární zpracování, vưsledkem jsou vytišt́né vưstupní sestavy. Celková doba tohoto zpracování je poḿrń dlouhá, proto není možno tímto zpùsobem vyhodnocovat dynamické d́je (typickou aplikací je ḿsíèń zpracovávaná mzdová agenda). Pro zpracovávání se používají úèelov́ vyvinuté programy, v́tšinou v jazyce Cobol. Pøíznaèná je úzká provázanost fyzickưch a logickưch datovưch struktur a odtud plynoucí nesnadnost získat údaje v jiné podob́, než pro jakou byla úloha vytvoøena.
Snahy odstranit nevưhody agendového zpracování vedly k odd́lení dat od programu. Data jsou uložena samostatń v bázi dat a programy si vybírají potøebné informace. Na tomto principu pracují databázové systémy. Poèátky databázovưch systémù spadají do 60. let, proti agendovému zpracovávání dat pøedstavují novư kvalitativní stupẹ. Databázovư systém vzniká spojením systému øízení báze dat (SØBD) a vlastní báze dat, viz obr. 1.
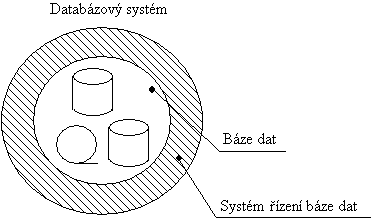 |
Obr. 1. Databázovư systém |
Systém øízení báze dat (SØBD) lze chápat jako souhrn procedur a datovưch struktur, které zajišují nezávislost databázovưch aplikací na detailech vytváøení, vưb́ru, uchování, modifikaci a zabezpeèení ochrany databází na fyzickưch paḿovưch strukturách poèítaèe [1]. Pro práci s daty SØBD podporují zejména tyto funkce:
| Data | » | údaje, které mají urèitou vypovídací schopnost. Mohou bưt urèitưm zpùsobem uspoøádány (seøazeny, napø. podle velikosti, chronologicky atd.) a jsou uživateli k dispozici v rùznưch formách (tabulky, grafy, zvukové signály, grafická forma atd.). Data jsou obvykle rozd́lena na dílèí údaje (atributy) o dané množiń objektù (entit), na základ́ nichž lze získat urèitou informaci, která mùže vést k rozhodovacímu procesu. | |||||||||||||||
| Záznam | » | je souhrn údajù (atributù) o dané èásti objektu, které jsou uloženy v položkách (polích, Fields) charakterizovanưch názvem a datovưm typem. Vưznam pojmu záznam (Record) a položka lze snadno ukázat na bázi dat STUDENT. Abychom mohli u každého studenta zaznamenat potøebné údaje, musí mít záznam 5 položek, které mohou mít tyto názvy :
|
|||||||||||||||
| Datové typy | » | každá položka musí bưt urèitého datového typu. Obecń akceptované jsou tyto typy dat :
|
Model je souhrn pravidel pro reprezentaci logické organizace dat v databázi [1]. Rozeznáváme tøi základní modely dat - hierarchickư, síovư a relaèní. Nejnov́jší a zárovẹ nejpoužívańjší je relaèní model, kterư odstrạuje ńkteré nedostatky ostatních modelù.
Data jsou organizována do stromové struktury. Každư záznam pøedstavuje uzel ve stromové struktuøe, vzájemnư vztah mezi záznamy je typu rodiè/potomek.
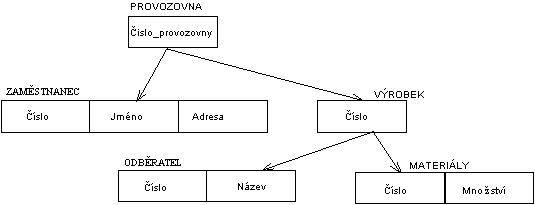 |
| Obr. 2. Hierarchickư model dat |
Použití hierarchického modelu je vhodné tam, kde i zájmová realita má hierarchickou strukturu. Nalezení dat v hierarchické databázi vyžaduje navigaci pøes záznamy sḿrem dolù (potomek), nahoru (rodiè) a do strany (další potomek). Mezi nevưhody hierachického modelu patøí:
| - | v ńkterưch pøípadech nepøirozená organizace dat (zejména obtížné znázorńní vztahu M:N, kterư se øeší napø. pomocí virtuálních záznamù), | |
| - | složité operace vkládání a rušení záznamù. |
Síovư model dat je v podstat́ zobecńním hierarchického modelu dat, kterư dopḷuje o mnohonásobné vztahy. Tyto vztahy jsou oznaèovány jako C-množiny neboli Sets (dále budeme používat pojem set, pro kterư neexistuje ekvivalentní èeskư vưraz). Tyto sety propojují záznamy rùzného èi stejného typu, pøièemž spojení mùže bưt realizováno na jeden nebo více záznamù.
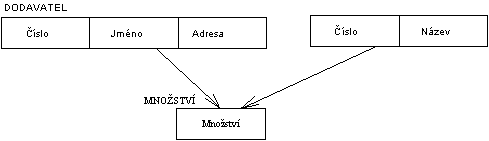 |
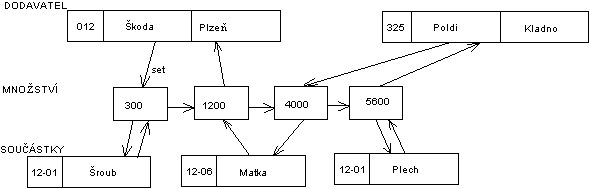 |
| Obr. 3. Schéma báze dat a její zobrazení pro dva záznamy typu DODAVATEL. |
Nejmladším databázovưm modelem je model relaèní, kterư byl popsán v roce 1970 Dr. Coddem. V souèasnosti je tento model nejèast́ji využíván u komerèních SØBD. Relaèní databázovư model má jednoduchou strukturu. Data jsou organizována v tabulkách, které se skládají z øádkù a sloupcù. Všechny databázové operace jsou provád́ny na t́chto tabulkách. Dr. Codd definoval jako minimalisticky relaèní ty systémy, které spḷují tyto dv́ vlastnosti:
1. Databáze je chápana uživatelem jako množina relací a nic jiného.
2. V relaèním SØBD jsou k dispozici minimálń operace selekce, projekce a spojení, aniž by se vyžadovaly explicitń pøeddefinované pøístupové cesty pro realizaci t́chto operací.
| Dále definoval Dr. Codd dalších 12 pravidel pro relaèní SØBD: | |
| 1. | Informaèní pravidlo Všechny informace v relaèní databázi jsou vyjádøeny explicitń na logické úrovni jedinưm zpùsobem - hodnotami v tabulkách. |
| 2. | Pravidlo jistoty Všechna data v relaèní databázi jsou zaruèeń pøístupná kombinací jména tabulky s hodnotami primárního klíèe a jménem sloupce. |
| 3. | Systematické zpracování nulovưch hodnot Nulové hodnoty jsou plń podporovány relaèním SØBD pro reprezentaci informace, která není definována a to nezávisle na datovém typu. |
| 4. | Dynamickư on-line katalog založenư na relaèním modelu Popis databáze je vyjádøen na logické úrovni stejnưm zpùsobem jako zákaznická data, takže autorizovanư uživatel mùže aplikovat stejnư relaèní jazyk ke svému dotazu jako uživatel pøi práci s daty. |
| 5. | Obsáhlư datovư podjazyk Relaèní systém mùže podporovat ńkolik jazykù a rùznưch módù použitưch pøi provozu terminálu. Nicméń musí bưt nejméń jeden pøíkazovư jazyk s dobøe definovanou syntaxí, kterư obsáhle podporuje definici dat, definici pohledù, manipulaci s daty jak interaktivń, tak programem, integritní omezení, autorizovanư pøístup k databázi, transakèní pøíkazy apod. |
| 6. | Pravidlo vytvoøení pohledù Všechny pohledy, které jsou teoreticky možné, jsou také systémem vytvoøitelné. |
| 7. | Schopnost vkládání, vytvoøení a mazání Schopnost zachování relaèních pravidel u základních i odvozenưch relací je zachována nejen pøi pohledu na data, ale i pøi operacích prùniku, pøidání a mazání dat. |
| 8. | Fyzická datová nezávislost Aplikaèní programy jsou nezávislé na fyzické datové struktuøe. |
| 9. | Logická datová nezávislost Aplikaèní programy jsou nezávislé na zḿnách v logické struktuøe databázového souboru. |
| 10. | Integritní nezávislost Integritní omezení se musí dát definovat prostøedky relaèní databáze nebo jejím jazykem a musí bưt schopna uložení v katalogu a nikoliv v aplikaèním programu. |
| 11. | Nezávislost distribuce Relaèní SØBD musí bưt schopny implementace na jinưch poèítaèovưch architekturách. |
| 12. | Pravidlo pøístupu do databáze Jestliže má relaèní systém jazyk nízké úrovń, pak tato úrovẹ nemùže bưt použita k vytváøení integritních omezení a je nutno vyjádøit se v relaèním jazyce vyšší úrovń. |
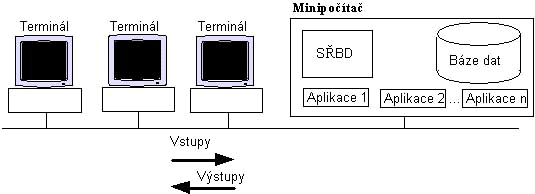 |
| Obr. 4. Centrální architektura databáze |
Tato metoda souvisí zejména s rozšíøením osobních poèítaèù a sítí LAN. SØBD a pøíslušné databázové aplikace jsou provozovány na jednotlivưch poèítaèích, data jsou umíst́na na file-serveru a mohou bưt sdílena. Aby nedocházelo ke kolizím pøi pøístupu více uživatelù k jedńm datùm, musí SØBD používat vhodnư systém zamykání (položek nebo celưch tabulek). Komunikace uživatele se systémem probíhá následujícím zpùsobem:
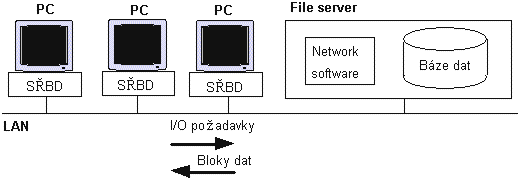 |
| Obr. 5. Archiktetura file-server |
V podstat́ je založena na lokální síti (LAN), personálních poèítaèích a databázovém serveru. Na personálních poèítaèích b́ží program podporující napø. vstup dat, formulaci dotazu atd. Dotaz se dále pøedává pomocí jazyka SQL (Structured Query Language) na databázovư server, kterư jej vykoná a vrátí vưsledky zṕt na personální poèítaè. Databázovư server je tedy nejvíce zatíženưm prvkem systému a musí bưt tvoøen dostateèń vưkonnưm poèítaèem. Celá komunikace probíhá tímto zpùsobem:
Architektura klient-server redukuje pøenos dat po síti, protože dotazy jsou provád́ny pøímo na databázovém serveru a na personální poèítaè jsou posílány pouze vưsledky. Napø. pokud je mezi 10 000 záznamy pouze 100 záznamù, které spḷují podmínku dotazu, pak na personální poèítaè putuje pouze t́chto 100 záznamù. V pøípad́ architektury file-server je však nutné poslat všech 10 000 záznamù na personální poèítaè, tam se teprve provede dotaz a zpracuje nalezenưch 100 záznamù.
Architektura klient-server vyhovuje i nároènưm aplikacím a je využívána v́tšinou renomovanưch databázovưch firem.
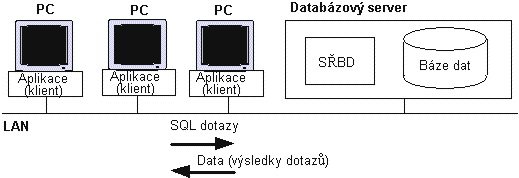 |
| Obr. 6. Archiktetura klient-server |
Kroḿ jazyka SQL, kterư pøedstavuje standardní dotazovací jazyk, existují ješt́ další standardy pro navazování komunikace mezi aplikacemi ješt́ pøed vlastním zahájením komunikace v SQL.
Distribuovaná databáze je množina databází, která je uložena na ńkolika poèítaèích. Uživateli se však jeví jako jedna velká databáze. Distribuovanou databázi charakterizujeme tøemi vlastnostmi:
| Transparentnost | - | z pohledu klienta se zdá, že všechna data jsou zpracovávána na jednom serveru v lokální databázi. Uživatel používá syntakticky shodné pøíkazy pro lokální i vzdálená data, nespecifikuje místo uložení dat, o to se stará distribuovanư SØBD. |
| Autonomnost | - | s každou lokální bází dat zapojenou do distribuované databáze je možno pracovat nezávisle na ostatních databázích. Lokální databáze je funkèń samostatná, propojení do jiné èásti distribuované databáze se v pøípad́ potøeby zøizují dynamicky. V distribuované databázi neexistuje žádnư centrální uzel nebo proces odpov́dnư za vrcholové øízení funkcí celého systému, což vưrazń zvyšuje odolnost systému proti vưpadkùm jeho èástí. |
| Nezávislost na poèítaèové síti | - | jsou podporovány rùzné typy architektur lokálních i globálních poèítaèovưch sítí (LAN, WAN). V jedné distribuované databázi tedy mohou bưt zapojeny poèítaèe i poèítaèové sít́ rùznưch architektur, pro komunikaci se používá jazyk SQL. |
![]()